Connect your source
In the sidebar, open Search Rail (under Rails), then click Connect source. Pick where your data lives. Raily connects to vector stores (Qdrant, Pinecone, Weaviate, Milvus, pgvector, Oracle), cloud storage, and CRMs like Salesforce.See Connect a vector store for the per-provider details.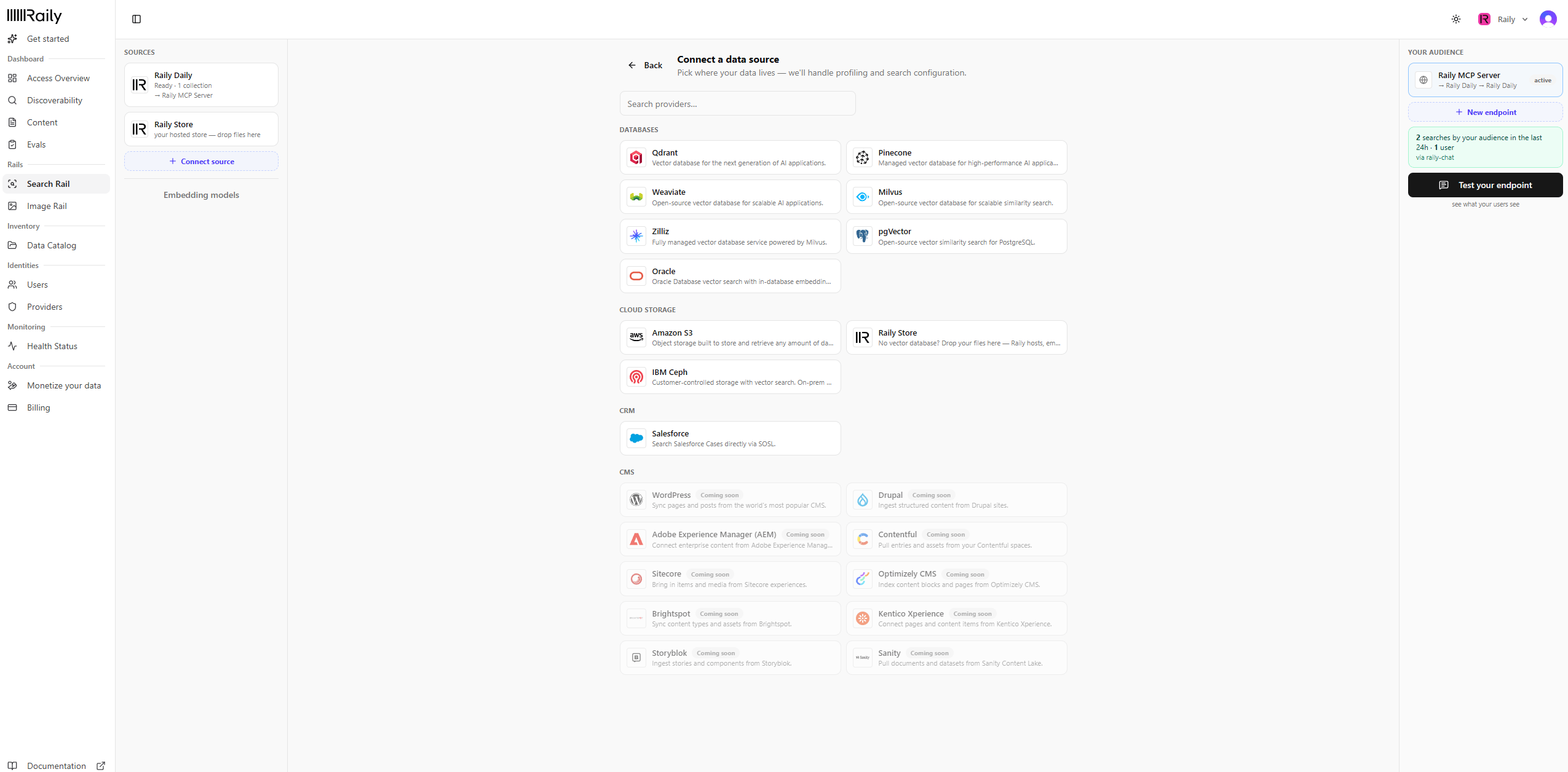
Pick collections and an embedding model
Name the source and confirm its credentials show Verified. Click Fetch Collections, toggle on each collection you want to search, and choose an embedding model. Raily only offers models that match how your data was embedded, so queries are embedded the same way as your corpus. Click Create Integration.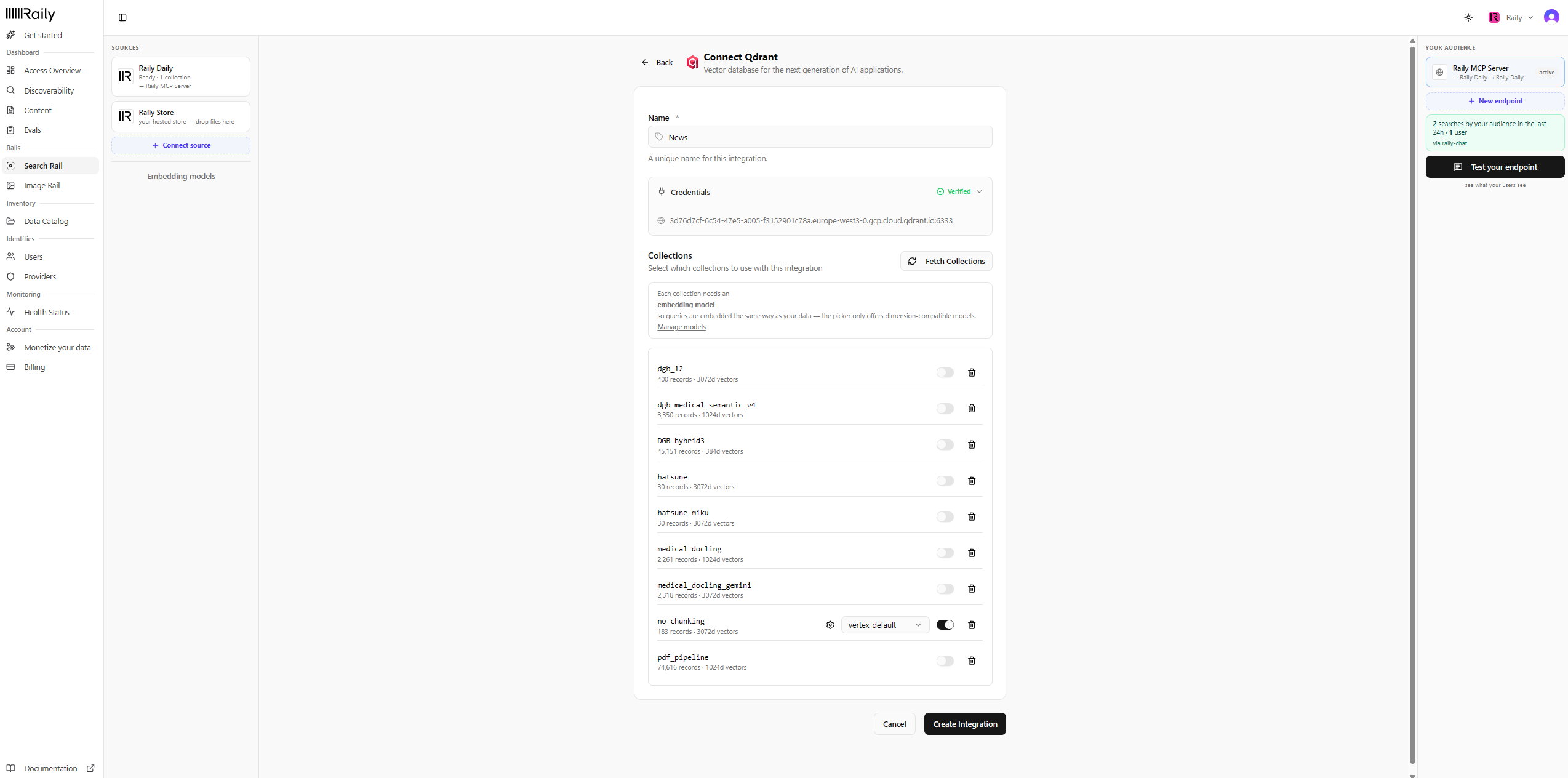
Let Raily build the search config
Raily profiles the collection and generates its search config for you. When it finishes, the collection shows Ready and the config is saved as v1 · latest. You can open Edit to tune it, or History to see past versions, anytime.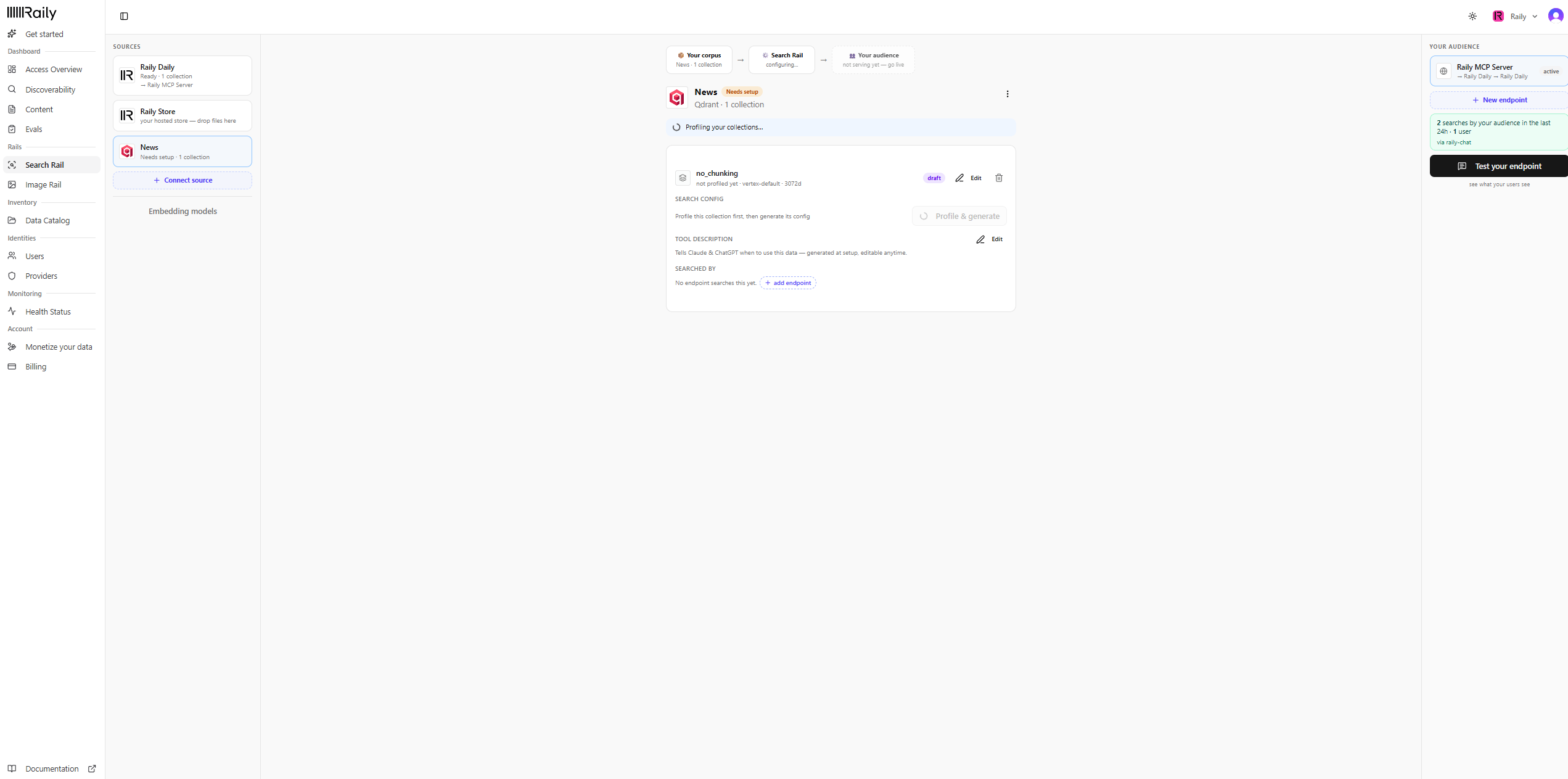
Point an endpoint at it and go live
Under Searched by, click add endpoint. You have two choices: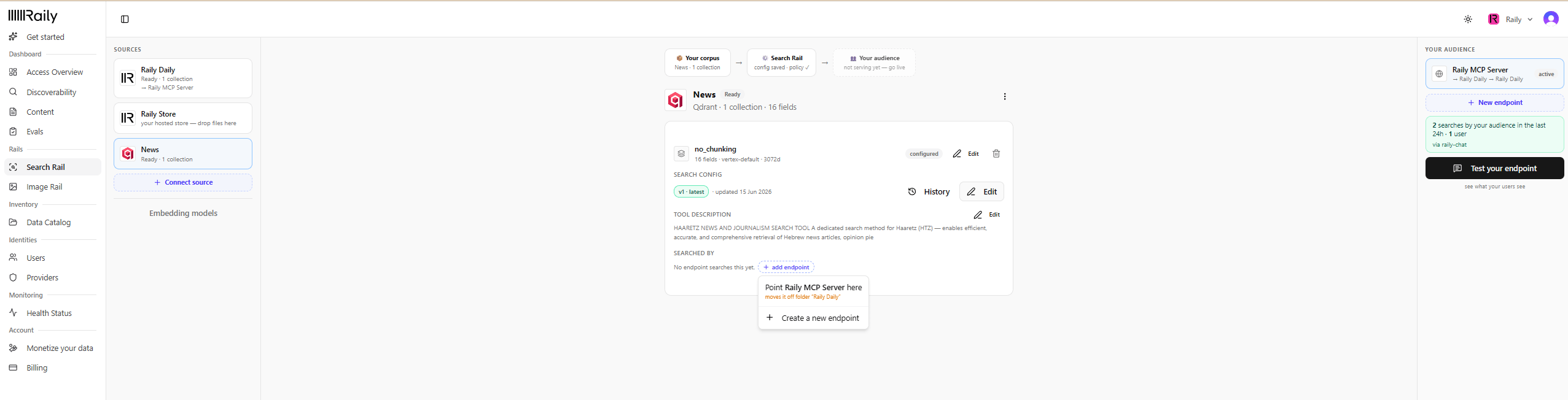
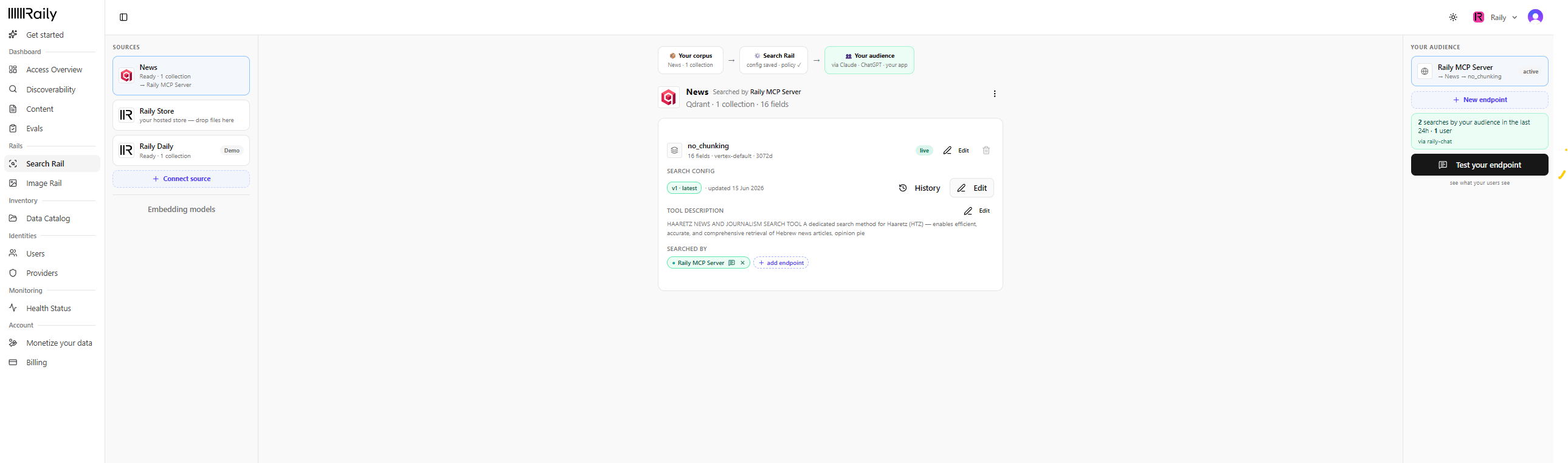
- Point an existing endpoint here (for example Point Raily MCP Server here). This moves the endpoint onto this collection.
- Create a new endpoint when this collection needs its own. See AI Endpoints for details.
Test your endpoint
Click Test your endpoint to preview exactly what your audience’s agents see. Ask a question in plain language. Raily searches your collection and answers with links back to the source. This page is an admin preview. Your audience never sees it. They ask from inside Claude, ChatGPT, or your app.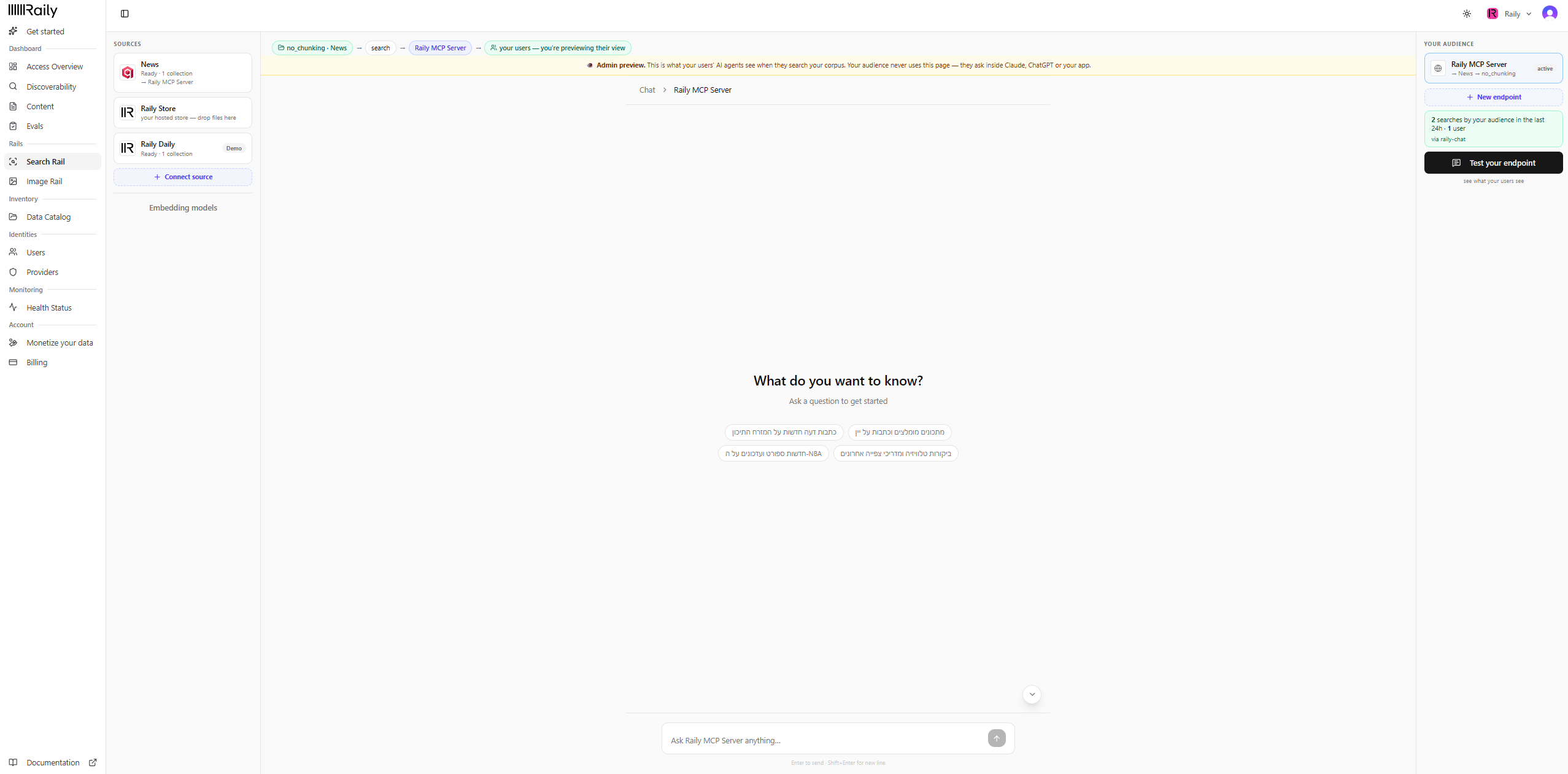
Connect your source to AI clients
Your endpoint is live. Now point an AI client at it so people can search your data from the tools they already use.Connect to Claude
Add your endpoint to Claude as a custom connector.
Connect to ChatGPT
Add your endpoint to ChatGPT as an app.